Huizhong Chen - Datasets
List of Data Sets
- Google I/O Dataset
- Names 100 Dataset
- Clothing Attributes Dataset
- Stanford Mobile Visual Search Dataset
- CNN 2-Hours Videos Dataset
Google I/O Dataset
The Google I/O Dataset contains slide and spoken text data crawled from 209 presentations in the Google I/O Conference (2010-2012), with 275 manually labeled ground truth relevance judgements. The dataset is particularly suitable for studying information retrieval using multi-modal data.
Download Dataset

- H. Chen, M. Cooper, D. Joshi, and B. Girod, "Multi-modal Language Models for Lecture Video Retrieval", ACM Multimedia (MM), October 2014. [Paper]
Back to Top
Names 100 Dataset
We present the Names 100 Dataset, which contains 80,000 unconstrained human face images, including 100 popular names and 800 images per name. The dataset can be used to study the relation between people's first names and their facial appearance, and train name classifiers which may be used for practical applications such as gender and age recognition.
Download Dataset

- Huizhong Chen, Andrew Gallagher, and Bernd Girod, "What's in a Name: First Names as Facial Attributes", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2013. [Paper]
- Huizhong Chen, Andrew Gallagher, and Bernd Girod, "The Hidden Sides of Names - Face Modeling with First Name Attributes", IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014. [Paper]
Back to Top
Clothing Attributes Dataset
We introduce the Clothing Attributes Dataset for promoting research in learning visual attributes for objects. The dataset contains 1856 images, with 26 ground truth clothing attributes such as "long-sleeves", "has collar", and "striped pattern". The labels were collected using Amazon Mechanical Turk.
Download Dataset
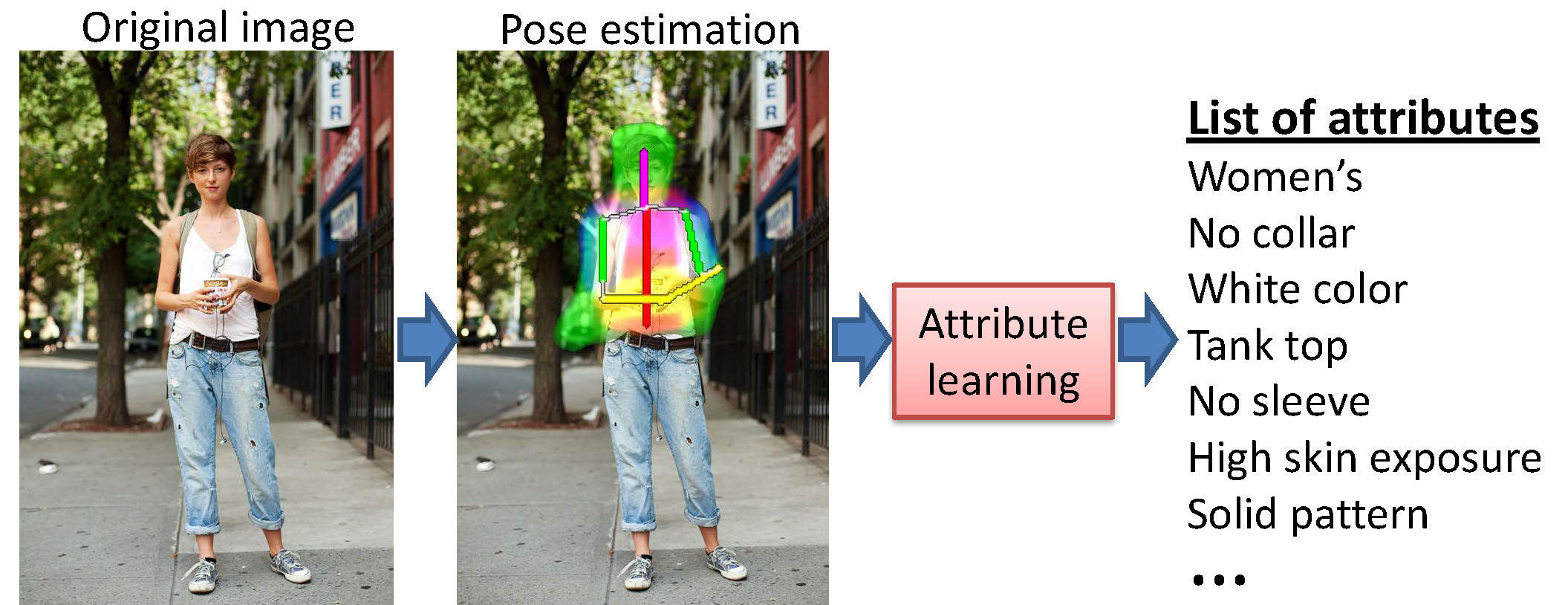
- H. Chen, A. Gallagher, and B. Girod, "Describing Clothing by Semantic Attributes", European Conference on Computer Vision (ECCV), October 2012. [Paper]
Back to Top
Stanford Mobile Visual Search Dataset
We propose the Stanford Mobile Visual Search dataset. The dataset contains camera-phone images of products, CDs, books, outdoor landmarks, business cards, text documents, museum paintings and video clips. The dataset has several key characteristics lacking in existing datasets: rigid objects, widely varying lighting conditions, perspective distortion, foreground and background clutter, realistic ground-truth reference data, and query data collected from heterogeneous low and high-end camera phones. We hope that the dataset will help push research forward in the field of mobile visual search.
Download Dataset

Reference |

Motorola Droid |

Nokia 5800 |

Apple iPhone |

Canon G11 |

Reference |

Motorola Droid |

Palm Pre |

Nokia E63 |

Canon G11 |

Reference |

Motorola Droid |

Palm Pre |

Nokia E63 |

Canon G11 |
References:
- V. Chandrasekhar, D. Chen, S. Tsai, N.-M. Cheung, H. Chen, G. Takacs, Y. Reznik, R. Vedantham, R. Grzeszczuk, J. Bach, and B. Girod, "The Stanford mobile visual search dataset", ACM Multimedia Systems Conference (MMSys), February 2011. [Paper]
Back to Top
CNN 2-Hours Videos Dataset
We present the CNN2h dataset, which can be used for evaluating systems that search videos using image queries. It contains 2 hours of video and 139 image queries with annotated ground truth (based on video frames extracted at 10 frames per second). The annotations also include: - 2,951 pairs of matching image queries and video frames - 21,412 pairs of non-matching image queries and video frames (which were verified to avoid visual similarities).
Download Dataset

- A. Araujo, M. Makar, V. Chandrasekhar, D. Chen, S. Tsai, H. Chen, R. Angst, and B. Girod, "Efficient video search using image queries", IEEE International Conference on Image Processing (ICIP), October 2014. [Paper]
Back to Top